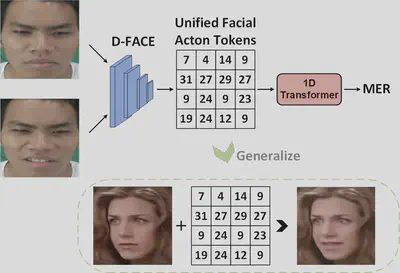
Unified Facial Action Representation Learning for Micro-Expression Analysis
Micro-expression recognition (MER) aims to recognize the emotion type of a subtle and rapid micro-expression clip. It is highly challenging due to subtle and rapid facial muscle movements and the scarcity of annotated data. In this work, we propose D-FACE, a Discrete Facial ACtion Encoding framework that leverages large-scale facial video data to pretrain an identity- and domain-invariant facial action tokenizer, for MER. For the first time, MER is shifted from relying on pixel-level motion descriptors to leveraging semantic-level facial action tokens, providing compact and generalizable representations of facial dynamics. Through extensive empirical analyses, we reveal that these tokens exhibit position-dependent semantics, motivating sequential modeling with a 1D Transformer. Furthermore, to explicitly bridge action tokens with human-understandable emotions, we introduce an emotion-description-guided CLIP (EDCLIP) alignment. Extensive experiments demonstrate that our method achieves not only state-of-the-art recognition accuracy but also high-quality cross-identity and even cross-domain micro-expression generation.
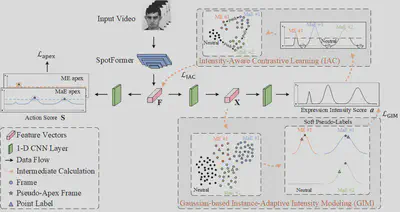
Gaussian-Based Instance-Adaptive Intensity Modeling for Point-Supervised Facial Expression Spotting
Point-supervised facial expression spotting (P-FES) aims to localize facial expression instances in untrimmed videos, requiring only a single timestamp label for each instance during training. In this research, we propose a two-branch framework for P-FES that incorporates a Gaussian-based instance-adaptive Intensity Modeling (GIM) module to model the expression intensity distribution of each instance for soft pseudo-labeling. Specifically, we (1) detect the pseudo-apex frame around each point label, (2) estimate the duration, and (3) construct a Gaussian distribution for each expression instance. We then assign soft pseudo-labels to pseudo-expression frames as intensity values based on the Gaussian distribution. Additionally, we introduce an Intensity-Aware Contrastive (IAC) loss to enhance discriminative feature learning and suppress neutral noise by contrasting neutral frames with expression frames of various intensities. Extensive experiments on several datasets demonstrate the effectiveness of our proposed framework.
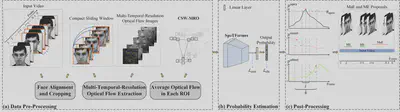
Multi-Scale Spatio-Temporal Transformer for Fully-Supervised Facial Expression Spotting
This research focuses on fully supervised facial expression spotting, which identifies periods where facial expressions occur in a video based on frame-level annotations. We propose a framework consisting of three key components: (1) a CSW-MRO feature that uses sliding windows with multi-temporal optical flow, where the window length is tailored to perceive complete micro-expressions and distinguish between general macro- and micro-expressions; (2) a multi-scale spatio-temporal Transformer (SpotFormer) that learns spatial and temporal relationships of regions of interest (ROIs) for frame-level probability estimation; and (3) supervised contrastive learning to improve the model’s ability to distinguish different types of expressions. Extensive experiments on several benchmarks show that our method outperforms state-of-the-art models, particularly in micro-expression spotting.
Multi-label Disengagement and Behavior Prediction in Online Learning
Student disengagement prediction in online learning environments is beneficial in various ways, especially to help provide timely cues to make some feedback or stimuli to the students. In this work, we propose a neural network-based model to predict students’ disengagement, as well as other behavioral cues, which might be relevant to students’ performance, using facial image sequences. For training and evaluating our model, we collected samples from multiple participants and annotated them with temporal segments of disengagement and other relevant behavioral cues with our multiple in-house annotators. We present prediction results of all behavior cues along with baseline comparison.
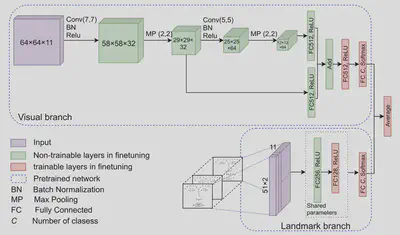
Facial expression recognition
Deep convolutional neural networks (CNNs) have established their feet in the ground of computer vision and machine learning, used in various applications. In this work, an attempt is made to learn a CNN for a task of facial expression recognition (FER). Our network has convolutional layers linked with an FC layer with a skip-connection to the classification layer. The motivation behind this design is that lower layers of a CNN are responsible for lower-level features, and facial expressions can be mainly encoded in low-to-mid level features. Hence, in order to leverage the responses from lower layers, all convolutional layers are integrated via FC layers. Moreover, a network with shared parameters is used to extract landmark motion trajectory features. These visual and landmark features are fused to improve performance. Our method is evaluated on the CK+ and Oulu-CASIA facial expression datasets.
Learning efficiency prediction from eye trajectories
Estimating how much a learner is engaged, concentrates, and comprehends a topic, which we call learners’ efficiency, is an essential step towards adaptive e-learning to automatically adjust the content or suggest resting. We explore the first step toward estimating learners’ efficiency with a certain learning task. From various possible signals, we choose eye trajectories captured by an eye tracker as eye trajectories are one of the modalities that can be directly affected by the learner’s status. We formulate the learners’ efficiency estimation as a binary classification problem and solve it with a deep neural network. We show that predicting learners’ efficiency is possible from eye trajectories, at least for a certain learning-related task at AUC of 70%. Performance varies learner by learner.